In a CQRS-based application, a Domain Model (as defined by Eric Evans and Martin Fowler) can be a very powerful mechanism to harness the complexity involved in the validation and execution of state changes. Although a typical Domain Model has a great number of building blocks, two of them play a major role when applied to CQRS: the Event and the Aggregate.
The following sections will explain the role of these building blocks and how to implement them using the Axon Framework.
Events are objects that describe something that has occurred in the application. A typical source of events is the Aggregate. When something important has occurred within the aggregate, it will raise an Event. In Axon Framework, Events can be any object. You are highly encouraged to make sure all events are serializable.
When Events are dispatched, Axon wraps them in a Message. The actual type of Message
used depends on the origin of the Event. When an Event is raised by an Aggregate, it is
wrapped in a DomainEventMessage (which extends EventMesssage).
All other Events are wrapped in an EventMessage. The
EventMessage contains a unique Identifier for the event, as well as a
Timestamp and Meta Data. The DomainEventMessage additionally contains the
identifier of the aggregate that raised the Event and the sequence number which allows
the order of events to be reproduced.
Even though the DomainEventMessage contains a reference to the Aggregate Identifier, you should always include that identifier in the actual Event itself as well. The identifier in the DomainEventMessage is meant for the EventStore and may not always provide a reliable value for other purposes.
The original Event object is stored as the Payload of an EventMessage. Next to the payload, you can store information in the Meta Data of an Event Message. The intent of the Meta Data is to store additional information about an Event that is not primarily intended as business information. Auditing information is a typical example. It allows you to see under which circumstances an Event was raised, such as the User Account that triggered the processing, or the name of the machine that processed the Event.
![[Note]](images/note.png) | Note |
|---|---|
|
In general, you should not base business decisions on information in the meta-data of event messages. If that is the case, you might have information attached that should really be part of the Event itself instead. Meta-data is typically used for auditing and tracing. |
Although not enforced, it is good practice to make domain events immutable, preferably by making all fields final and by initializing the event within the constructor.
| Note |
|---|---|
|
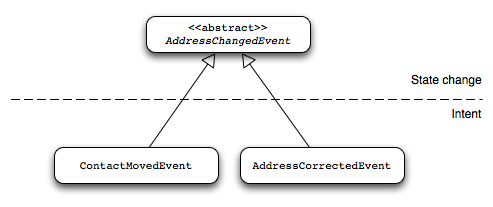
Although Domain Events technically indicate a state change, you should try to
capture the intention of the state in the event, too. A good practice is to use an
abstract implementation of a domain event to capture the fact that certain state has
changed, and use a concrete sub-implementation of that abstract class that indicates
the intention of the change. For example, you could have an abstract
|
When dispatching an Event on the Event Bus, you will need to wrap it in an (Domain)
Event Message. The GenericEventMessage is an implementation that allows you
to wrap your Event in a Message. You can use the constructor, or the static
asEventMessage() method. The latter checks whether the given parameter
doesn't already implement the Message interface. If so, it is either
returned directly (if it implements EventMessage,) or it returns a new
GenericEventMessage using the given Message's payload and
Meta Data.
An Aggregate is an entity or group of entities that is always kept in a consistent state. The aggregate root is the object on top of the aggregate tree that is responsible for maintaining this consistent state.
| Note |
|---|---|
|
The term "Aggregate" refers to the aggregate as defined by Evans in Domain Driven Design: “A cluster of associated objects that are treated as a unit for the purpose of data changes. External references are restricted to one member of the Aggregate, designated as the root. A set of consistency rules applies within the Aggregate's boundaries. ” A more extensive definition can be found on: http://domaindrivendesign.org/freelinking/Aggregate. |
For example, a "Contact" aggregate could contain two entities: Contact and Address. To keep the entire aggregate in a consistent state, adding an address to a contact should be done via the Contact entity. In this case, the Contact entity is the appointed aggregate root.
In Axon, aggregates are identified by an Aggregate Identifier. This may be any object, but there are a few guidelines for good implementations of identifiers. Identifiers must:
-
implement equals and hashCode to ensure good equality comparison with other instances,
-
implement a toString() method that provides a consistent result (equal identifiers should provide an equal toString() result), and
-
preferably be serializable.
The test fixtures (see Chapter 8, Testing) will verify these
conditions and fail a test when an Aggregate uses an incompatible identifier.
Identifiers of type String, UUID and the numeric types are
always suitable.
| Note |
|---|---|
|
It is considered a good practice to use randomly generated identifiers, as opposed to sequenced ones. Using a sequence drastically reduces scalability of your application, since machines need to keep each other up-to-date of the last used sequence numbers. The chance of collisions with a UUID is very slim (a chance of 10−15, if you generate 8.2 × 10 11 UUIDs). Furthermore, be careful when using functional identifiers for aggregates. They have a tendency to change, making it very hard to adapt your application accordingly. |
In Axon, all aggregate roots must implement the
AggregateRoot
interface. This interface describes the basic operations needed by the
Repository to store and publish the generated domain events. However, Axon
Framework provides a number of abstract implementations that help you writing
your own aggregates.
| Note |
|---|---|
|
Note that only the aggregate root needs to implement the
|
The AbstractAggregateRoot is a basic implementation that provides
a registerEvent(DomainEvent) method that you can call in your
business logic method to have an event added to the list of uncommitted events.
The AbstractAggregateRoot will keep track of all uncommitted
registered events and make sure they are forwarded to the event bus when the
aggregate is saved to a repository.
Axon framework provides a few repository implementations that can use event
sourcing as storage method for aggregates. These repositories require that
aggregates implement the
EventSourcedAggregateRoot
interface. As with
most interfaces in Axon, we also provide one or more abstract implementations to
help you on your way.
The interface
EventSourcedAggregateRoot
defines an extra method,
initializeState(), on top of the
AggregateRoot
interface. This method initializes an aggregate's state based on an event
stream.
Implementations of this interface must always have a default no-arg constructor. Axon Framework uses this constructor to create an empty Aggregate instance before initialize it using past Events. Failure to provide this constructor will result in an Exception when loading the Aggregate from a Repository.
The AbstractEventSourcedAggregateRoot implements all methods on
the EventSourcedAggregateRoot interface. It defines an abstract
handle() method, which you need to implement with the actual
logic to apply state changes based on domain events. When you extend the
AbstractEventSourcedAggregateRoot, you can register new events
using apply(). This method will register the event to be committed
when the aggregate is saved, and will call the handle() method with
the event as parameter. You need to implement this handle() method
to apply the state changes represented by that event. Below is a sample
implementation of an aggregate.
public class MyAggregateRoot extends AbstractEventSourcedAggregateRoot { private String aggregateIdentifier; private String someProperty; public MyAggregateRoot(String id) { apply(new MyAggregateCreatedEvent(id)); } // constructor required for reconstruction protected MyAggregateRoot() { } public void handle(DomainEvent event) { if (MyAggregateCreatedEvent.class.isAssignableFrom(event.getPayloadType())) { // make sure to always initialize the aggregate identifier this.aggregateIdentifier = ((MyAggregateCreatedEvent) this.getPayload()).getMyIdentifier(); // do something with someProperty } // and more if-else-if logic here } public Object getAggregateIdentifier() { return aggregateIdentifier; } }
| isAssignableFrom versus instanceof |
|---|---|
|
Note that the code sample used |
As you see in the example above, the implementation of the
handle()
method can become quite verbose and hard to read. The
AbstractAnnotatedAggregateRoot
can help. The
AbstractAnnotatedAggregateRoot
is a specialization of the
AbstractAggregateRoot
that provides
@EventHandler
annotation support to your aggregate. Instead of a single
handle()
method, you can split the logic in separate methods, with names that you may
define yourself. Just annotate the event handler methods with
@EventHandler, and the
AbstractAnnotatedAggregateRoot
will invoke the right method for
you.
| Note |
|---|---|
|
Note that |
public class MyAggregateRoot extends AbstractAnnotatedAggregateRoot { @AggregateIdentifier private String aggregateIdentifier; private String someProperty; public MyAggregateRoot(String id) { apply(new MyAggregateCreatedEvent(id)); } // constructor needed for reconstruction protected MyAggregateRoot() { } @EventHandler private void handleMyAggregateCreatedEvent(MyAggregateCreatedEvent event) { // make sure identifier is always initialized properly this.aggregateIdentifier = event.getMyAggregateIdentifier(); // do something with someProperty } }
@EventHandler annotated methods are resolved using specific
rules. These rules are thorougly explained in Section 6.2.2, “Annotated Event Handler”.
| Using private methods |
|---|---|
|
Event handler methods may be private, as long as the security settings of the JVM allow the Axon Framework to change the accessibility of the method. This allows you to clearly separate the public API of your aggregate, which exposes the methods that generate events, from the internal logic, which processes the events. Most IDE's have an option to ignore "unused private method" warnings for
methods with a specific annotation. Alternatively, you can add an
|
The AbstractAnnotatedAggregateRoot also requires that the field
containing the aggregate identifier is annotated with
@AggregateIdentifier. If you use JPA and have JPA annotations
on the aggregate, Axon can also use the @Id annotation provided by
JPA.
Complex business logic often requires more than what an aggregate with only an aggregate root can provide. In that case, it important that the complexity is spread over a number of entities within the aggregate. When using event sourcing, not only the aggregate root needs to use event to trigger state transitions, but so does each of the entities within that aggregate.
Axon provides support for event sourcing in complex aggregate structures. All
entities other than the aggregate root need to implement
EventSourcedEntity (but extending
AbstractEventSourcedEntity or AbstractAnnotatedEntity
makes implementing these entities easier). The
EventSourcedAggregateRoot implementations provided by Axon
Framework are aware of these entities and will call their event handlers when
needed.
When an entity (including the aggregate root) applies an Event, it is registered
with the Aggregate Root. The aggregate root applies the event locally first. Next,
it will evaluate all fields annotated with @EventSourcedMember for any
implementations of EventSourcedEntity and handle the event on them.
Each entity does the same thing to its fields.
To register an Event, the Entity must know about the Aggregate Root. Axon will
automatically register the Aggregate Root with an Entity before applying any Events
to it. This means that Entities (in constrast to the Aggregate Root) should never
apply an Event in their constructor. Non-Aggregate Root Entities should be created
in an @EventHandler annotated method in their parent Entity (as
creation of an entity can be considered a state change of the Aggregate). Axon will
ensure that the Aggregate Root is properly registered in time. This also means that
a single Entity cannot be part of more than one aggregate at any time.
Fields that (may) contain child entities must be annotated with
@EventSourcedMember. This annotation may be used on a number of
field types:
-
directly referenced in a field;
-
inside fields containing an
Iterable(which includes all collections, such asSet,List, etc); -
inside both they keys and the values of fields containing a
java.util.Map
If the value contained in an @EventSourcedMember annotated field does
not implement EventSourcedEntity, it is simply ignored.
If you need to reference an Entity from any other location than the above
mentioned, you can override the getChildEntities() method. This method
should return a Collection of entities that should be notified of the
Event. Note that each entity is invoked once for each time it is located in the
returned Collection.
Note that in high-performance situations, the reflective approach to finding child
entities can be costly. In that case, you can override the
getChildEntities() method.